As a database professional, I’ve optimized my SQL Server Management Studio (SSMS) settings for maximum efficiency. Here’s a visual breakdown of my key configurations:
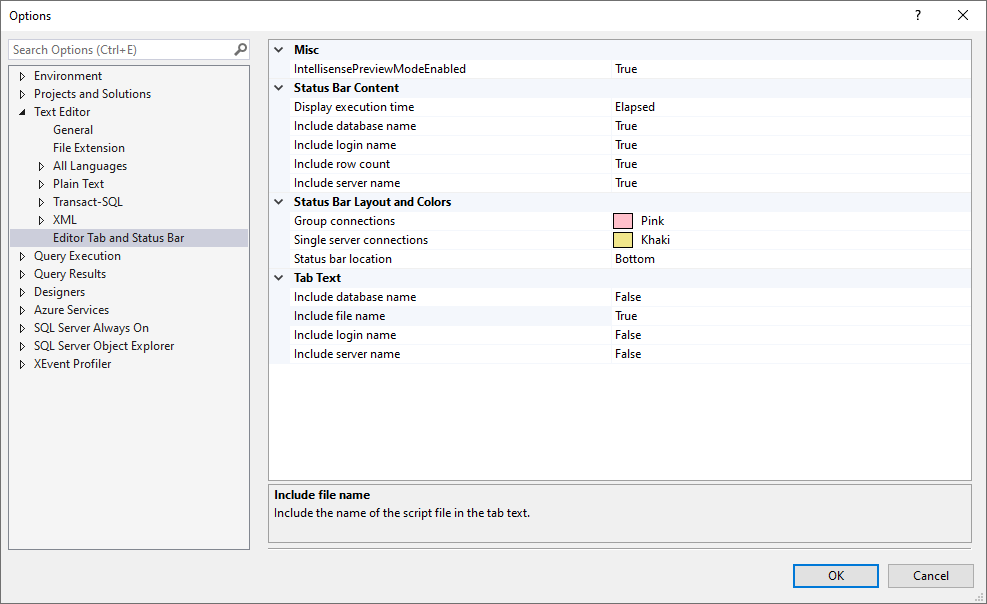
1. Editor Tab and Status Bar
Status bar shows execution time, database name, login, row count, and server
Pink for group connections, khaki for single server
Tab text includes only the file name
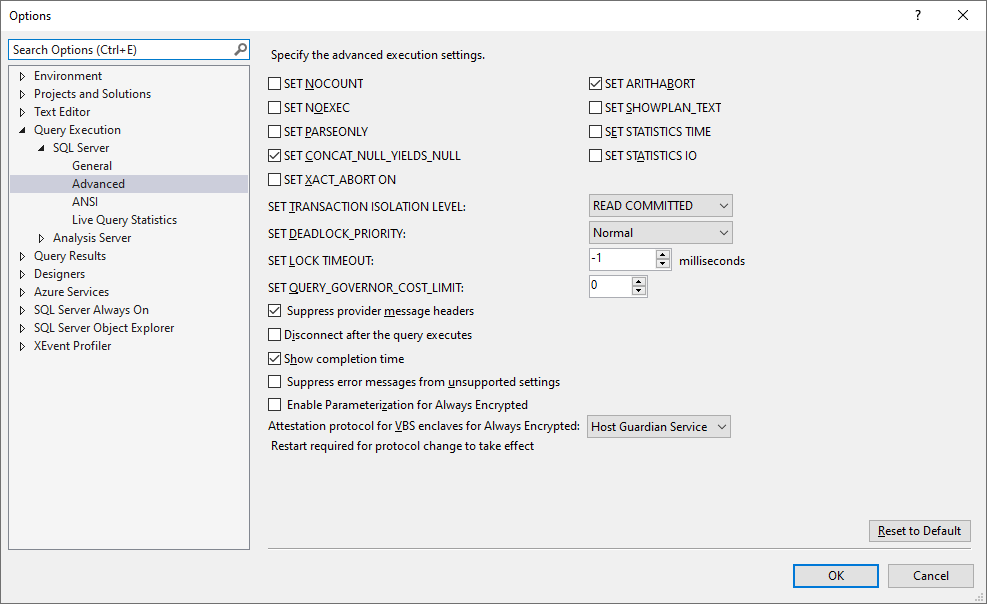
2. Advanced Execution Settings
SET CONCAT_NULL_YIELDS_NULL and SET ARITHABORT enabled
Transaction isolation: READ COMMITTED
Suppressed provider message headers
Completion time shown after query execution
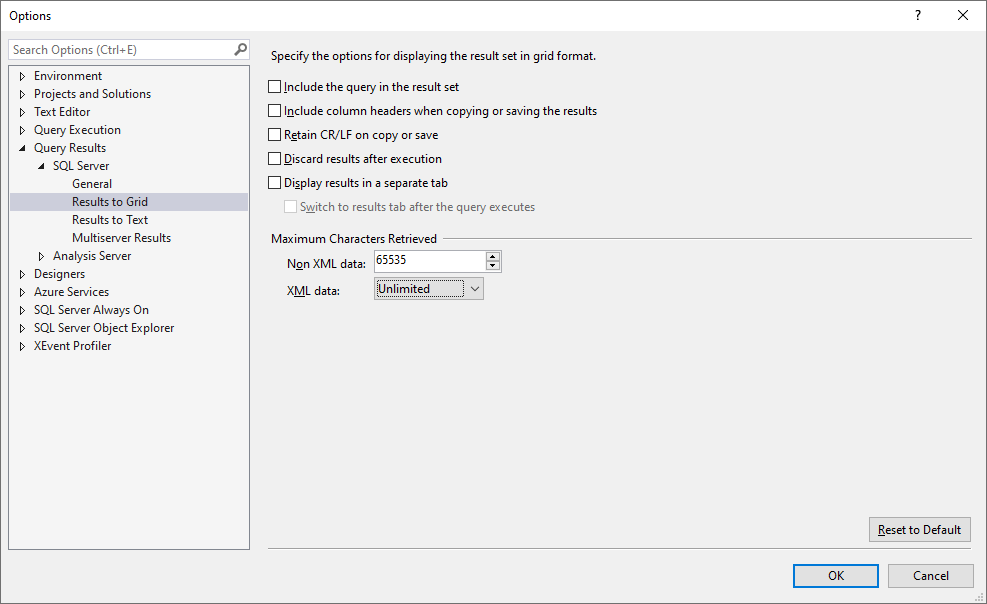
3. Query Results to Grid
Max characters for non-XML: 65535
XML data: Unlimited
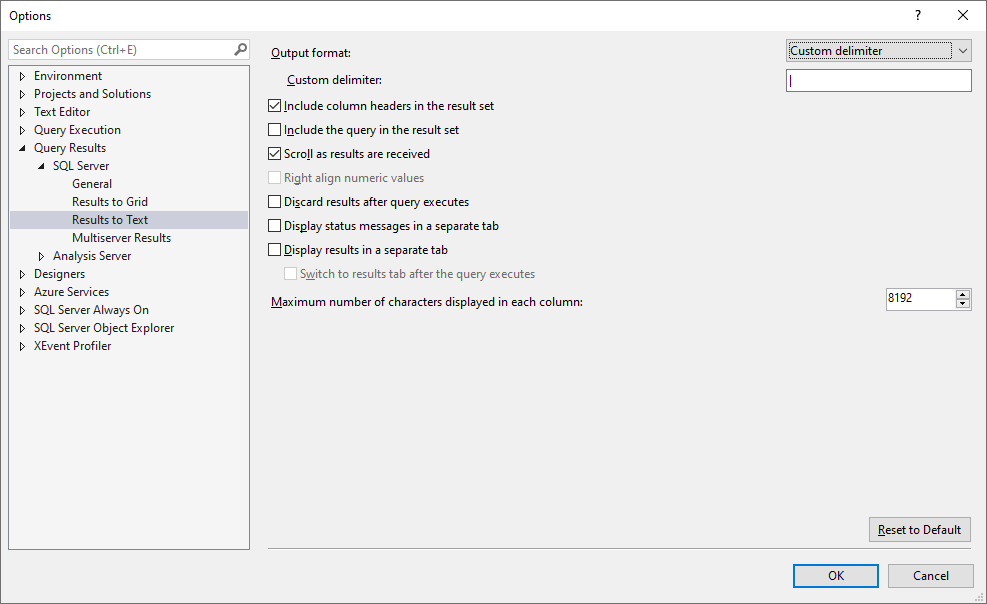
4. Query Results to Text
Custom delimiter: | (vertical bar)
Include column headers
Scroll as results are received
Max characters per column: 8192
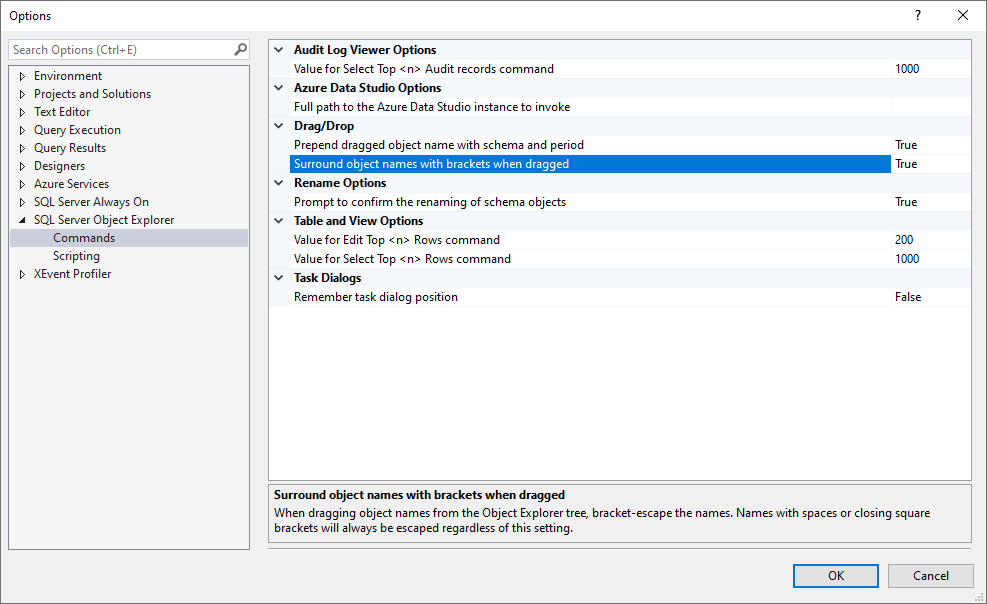
5. SQL Server Object Explorer Options
Audit Log: Top 1000 records
Drag-and-drop: Prepend schema, surround with brackets
Prompt for schema object renaming
Edit Top: 200 rows
Select Top: 1000 rows
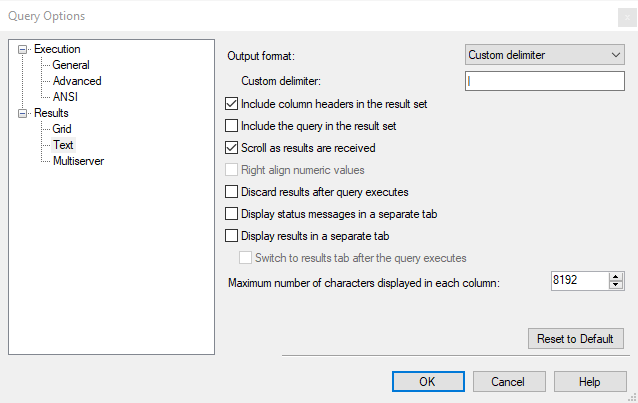
6. Query Output Formatting
Custom delimiter: | (pipe character)
Include column headers
Scroll as results are received
Max characters per column: 8192
These settings streamline my SSMS workflow. Adjust them to fit your needs and boost your productivity!
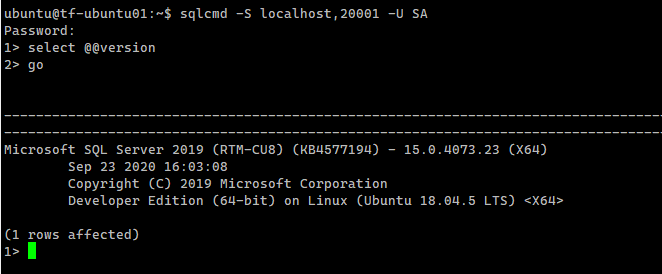
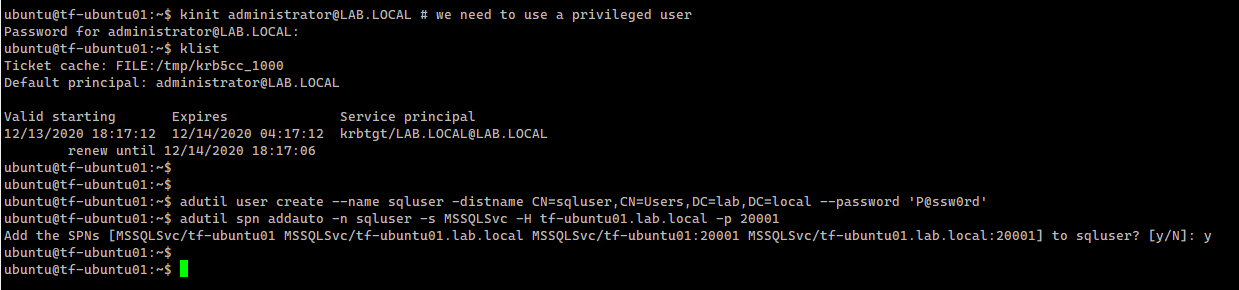
Microsoft just released the adutilin public preview which is a CLI based utility developed to ease the AD authentication configuration for both SQL Server on Linux and SQL Server Linux containers.
We don’t need to switch to a Windows machine to create the AD user for SQL Server and setting SPNs.
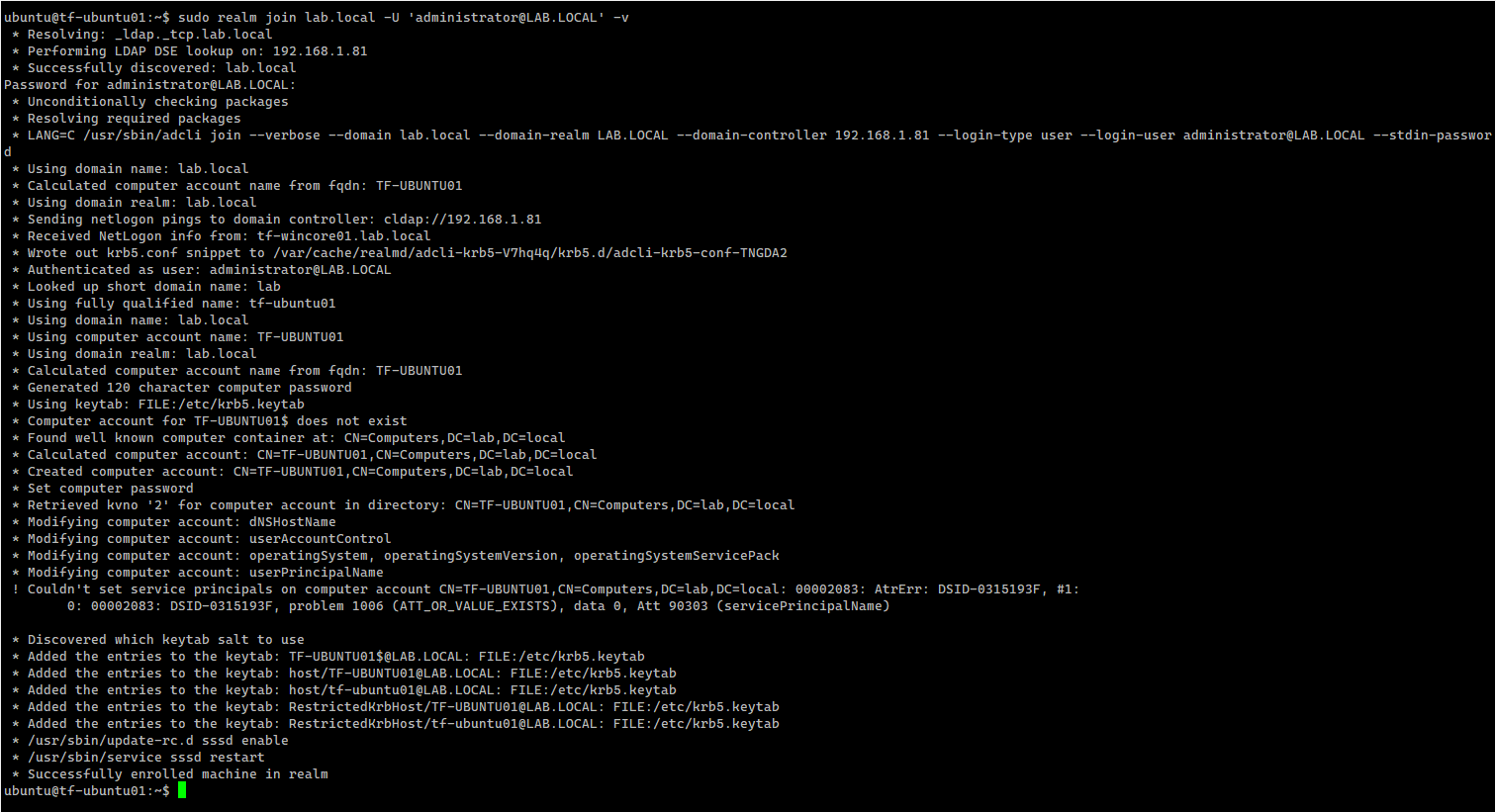
In the following steps I will try to install a SQL Server instance on Linux using just the Linux CLI tool adutil.
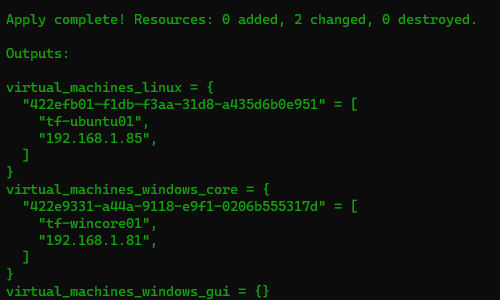
We will need 2 VMs:
tf-wincore01.lab.local – Domain Controller (DC) running on Windows Server 2019 Core (will host the lab.local domain)
tf-ubuntu01.lab.local – Ubuntu 18.04 LTS – SQL Server Instance on port 20001 will be installed here
I will be creating a brand new environment for this test and I am using Terraform to provision the VMs .
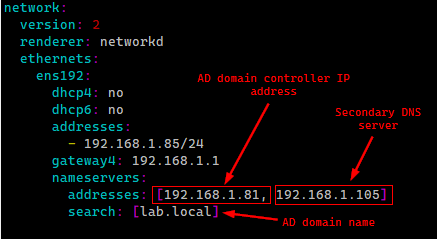
Prepare the Domain Controller
Once the VMs are created we need to configure the domain controller:
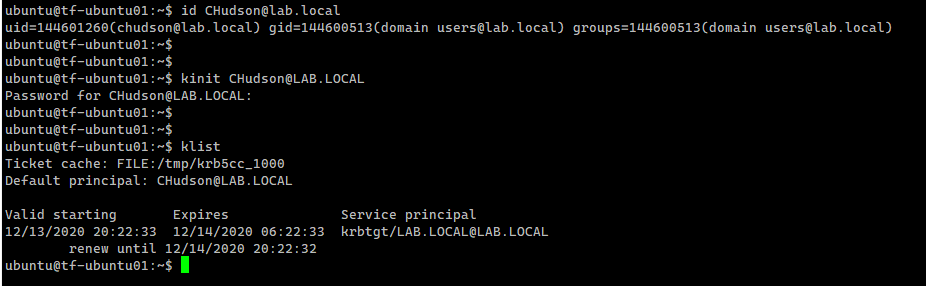
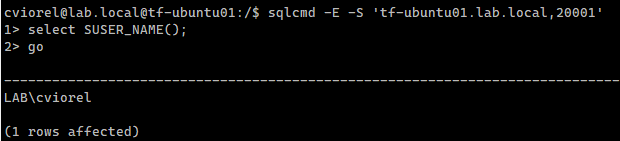
Let’s verify that we can now gather information about a user from the domain, and that we can acquire a
Kerberos ticket as that user.
The following example uses id, kinit, and klist commands for this.
1
2
3
id CHudson@lab.local
kinit CHudson@LAB.LOCAL
klist
Install adutil
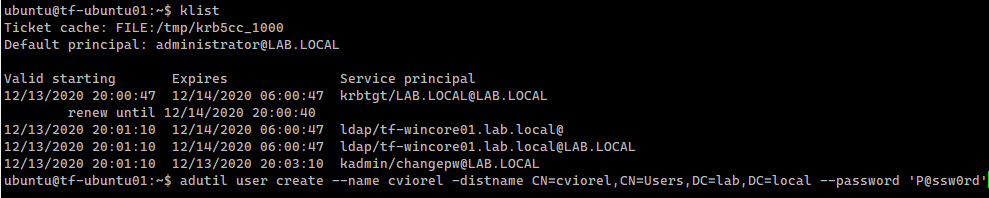
We now need to install the adutil so we can interact with the Domain Controller directly from the Linux box.
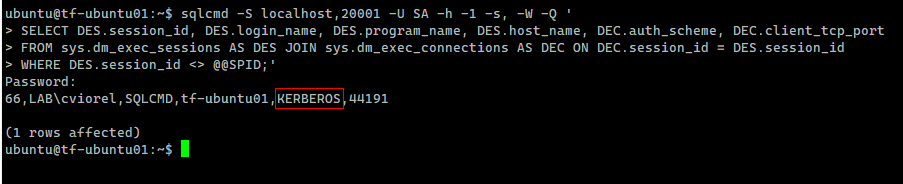
FROM sys.dm_exec_sessions AS DES JOIN sys.dm_exec_connections AS DEC ON DEC.session_id = DES.session_id
WHERE DES.session_id <> @@SPID;'
Conclusion
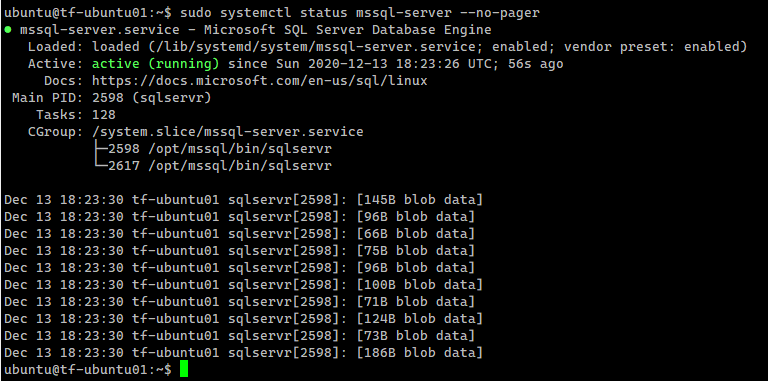
Our setup is now complete and we managed to perform all the required operations from a Linux machine.
The same can be applied to provision SQL Server running on Linux containers.
This also should apply if you’re running in the cloud.
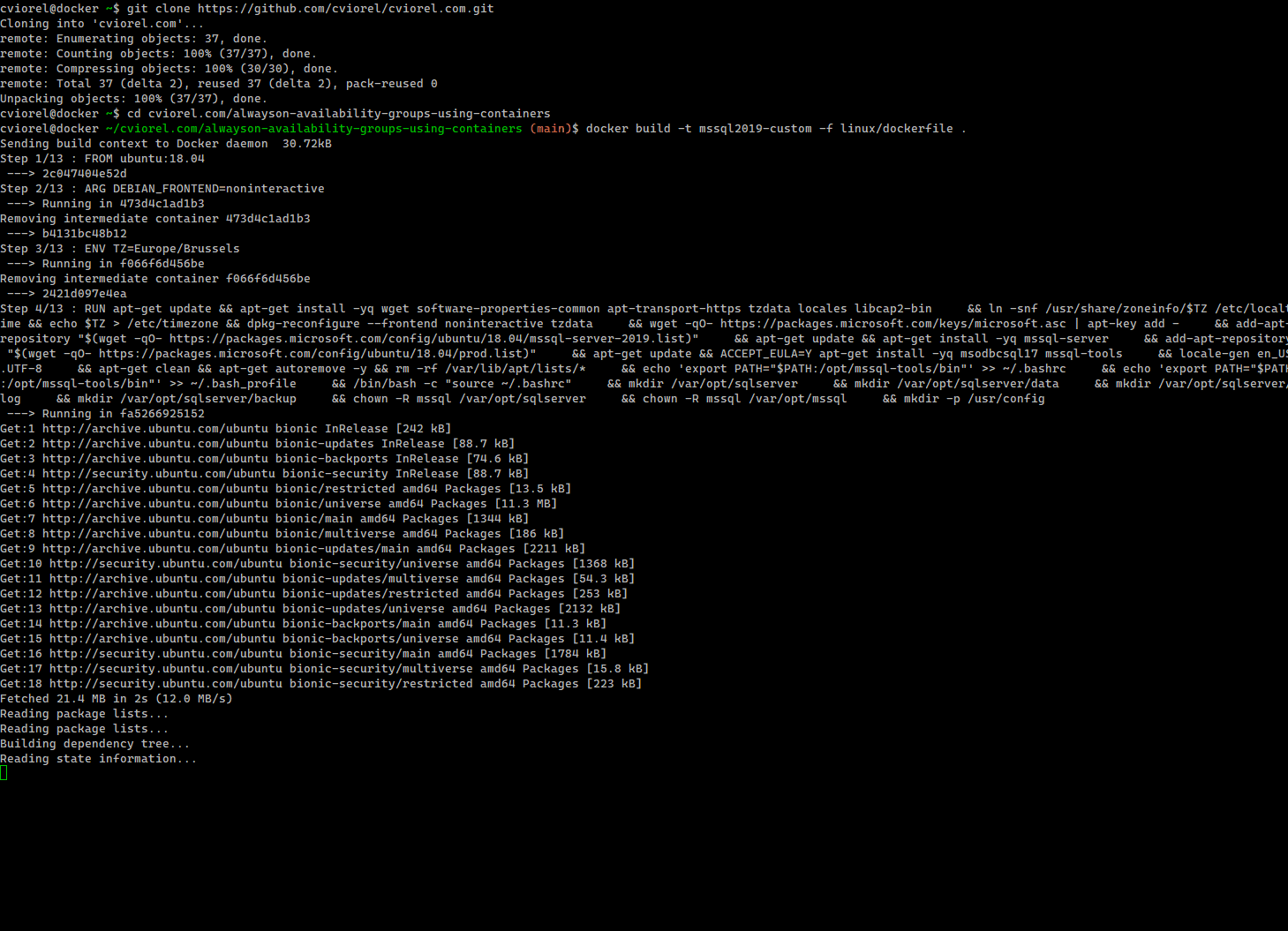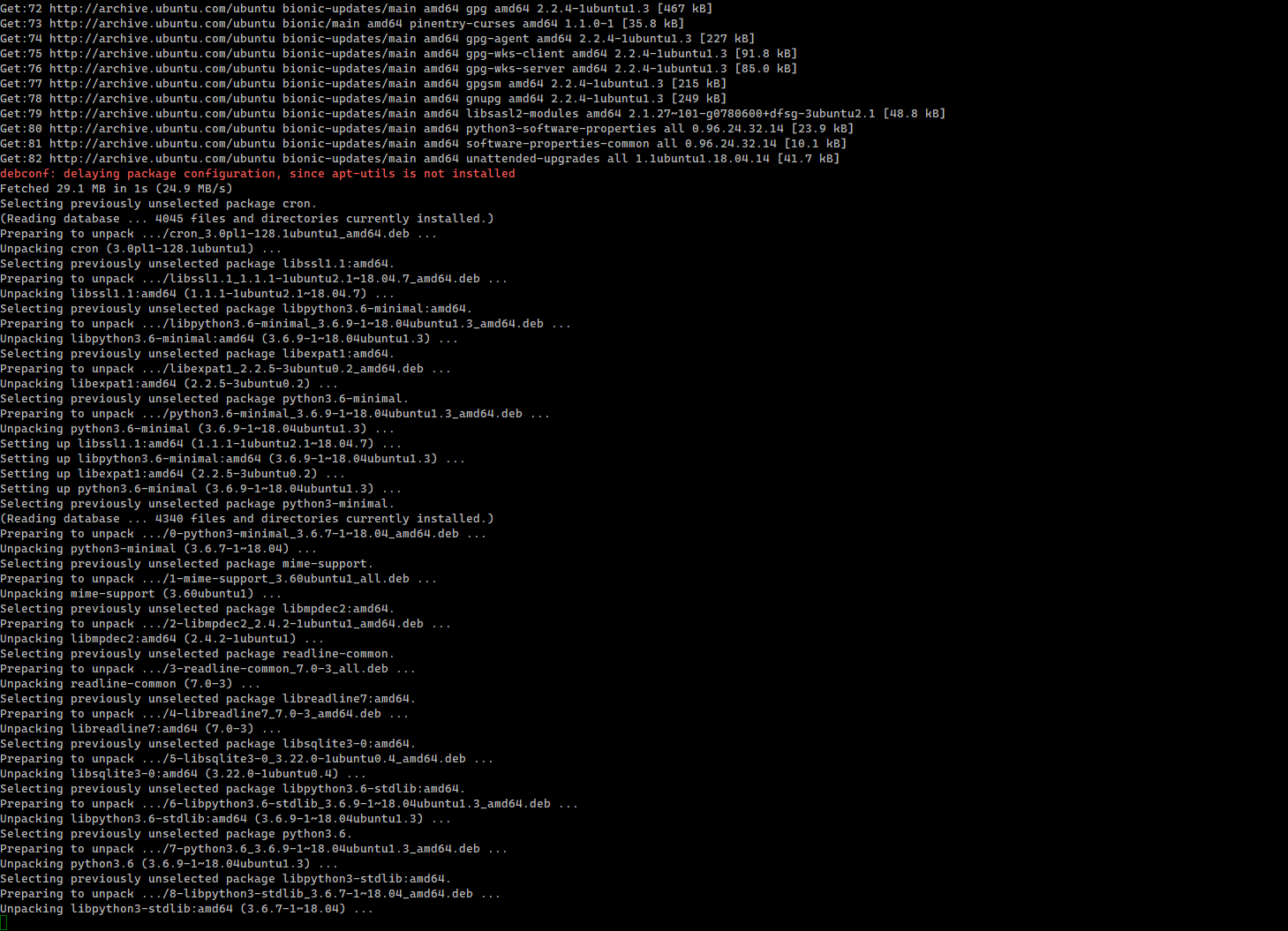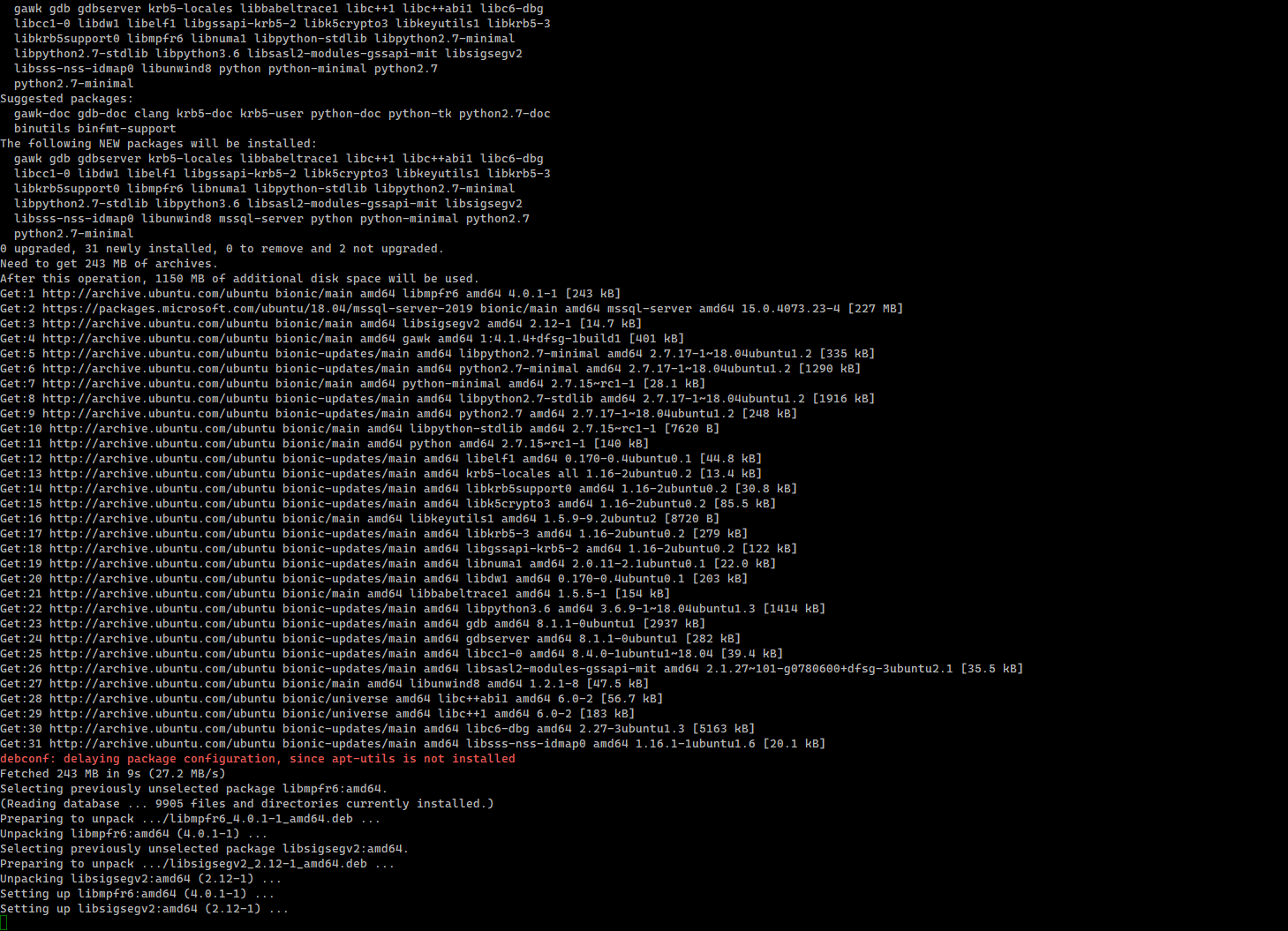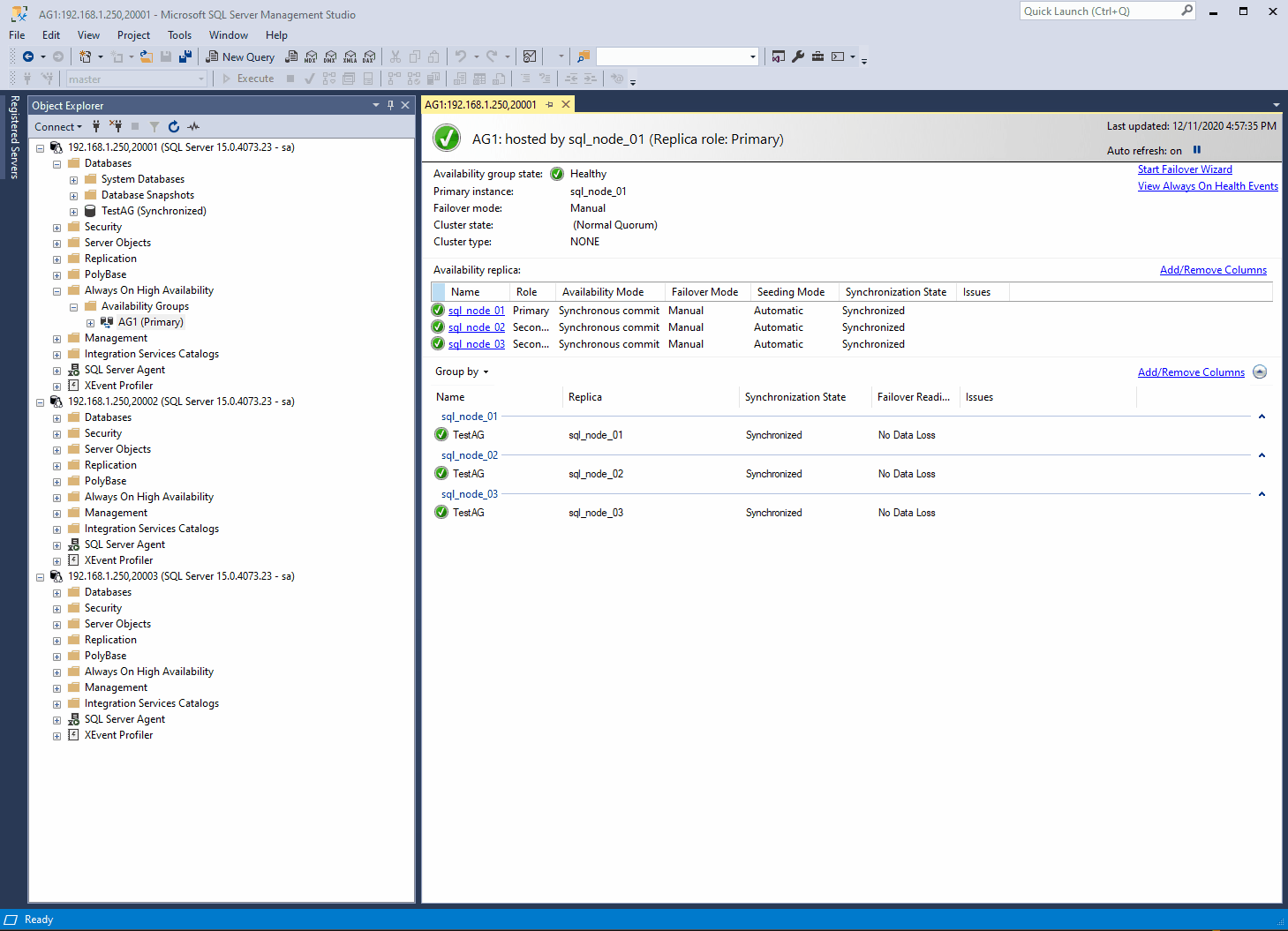
As a SQL Server person, I usually need to work with full blown Availability Groups for my various test scenarios.
I need to have a reliable and consistent way to rebuild the whole setup, multiple times a day.
For this purpose, docker containers are a perfect fit.
This approach will serve multiple scenarios (tsql development, performance tuning, infrastructure changes, etc.)
Target
Using the process I’ll explain below, I will deploy:
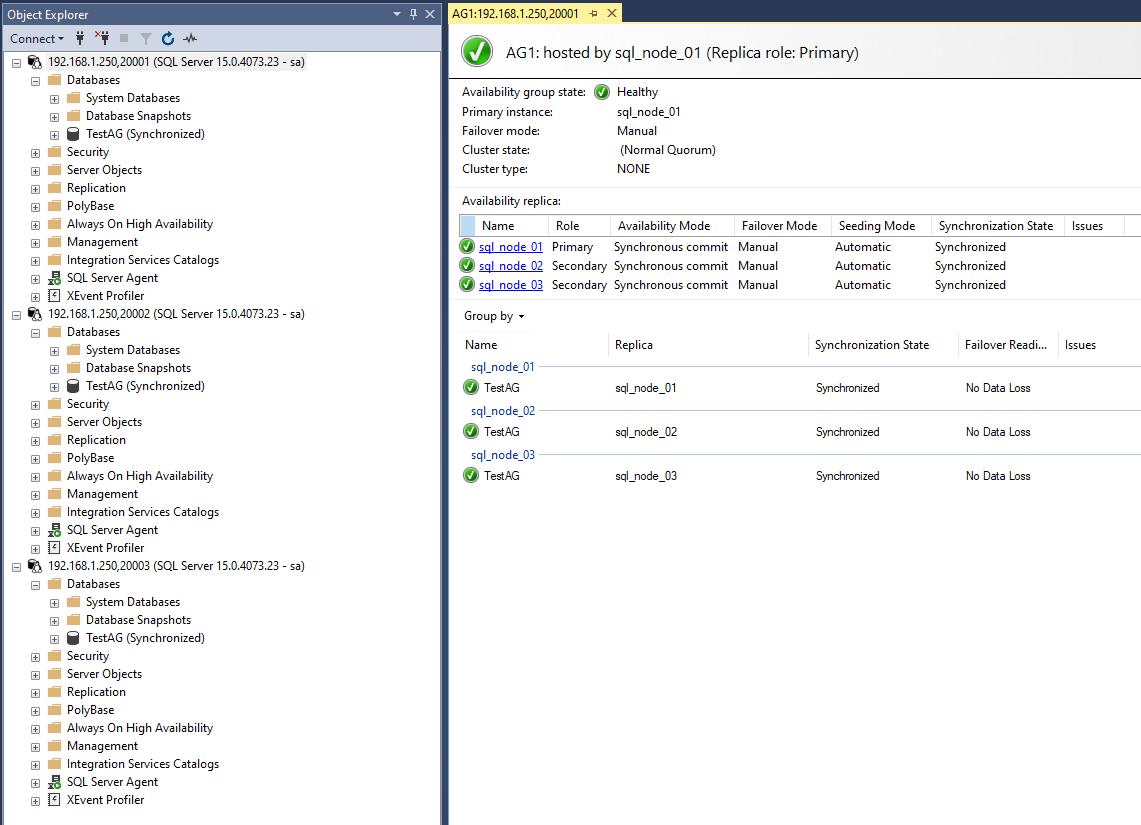
3 nodes running SQL Server 2019 Dev on top of Ubuntu 18.04
1 Clusterless Availability Group (also known as Read-Scale Availability Group)
Note that our Clusterless AG is not a high availability or disaster recovery solution.
It only provides a mechanism to synchronize databases across multiple servers (containers).
Only manual failover without data loss and forced failover with data loss is possible when using Read-Scale availability groups.
For production ready and true HA and DR one should look into traditional availability groups running on top of Windows Failover Cluster.
Another viable solution is to run SQL Server instance on Kubernetes in Azure Kubernetes Service (AKS), with persistent storage for high availability.
How
The workflow consist of the following steps:
prepare a custom docker image running Ubuntu 18.04 and SQL Server 2019
create a configuration file that will be used by docker-compose to spin up the 3 nodes
The actual build of the Availability Group will be performed by the entrypoint.sh script that will run on all the containers based on the image we just created.
The entrypoint.sh file is used to configure the container.
We just need to add a few .sql scripts that will get executed using sqlcmd utility.
In this case is the ag.sql file that contains the commands to create logins, certificates, endpoints and finally the Availability Group.
Remember, we’re using a Clusterless Availability Group, so the SQL Server service on Linux uses certificates to authenticate communication between the mirroring endpoints.
In a matter of minutes I have a fully working AG.
Credentials
During the build of the docker image and to create the AG I will need to specify various variables and credentials.
For production environments the recommended approach to manage secrets is to use a vault.
For my case I’m storing various variables and credentials in plain text files in the env folder.
Docker will parse those files and they will be available as environment variables.
sapassword.env – this contains the SA password and it’s needed when the custom image is built.
1
SA_PASSWORD=Str0ngPa$$w0rdForSA!
sqlserver.env – various variables are set here and are needed when the custom image is built.
1
2
3
4
5
6
ACCEPT_EULA=Y
MSSQL_DATA_DIR=/var/opt/sqlserver/data
MSSQL_LOG_DIR=/var/opt/sqlserver/log
MSSQL_BACKUP_DIR=/var/opt/sqlserver/backup
MSSQL_PID=Developer
MSSQL_AGENT_ENABLED=1
miscpassword.env – will be needed to create the login and certificate needed by the Availability Group. This file is actually added to the container and it will be deleted after the Availability Group is created.
The advantage of this approach is that I have only one place where I store all these variables and credentials, but as I mentioned earlier, it’s not a proper solution from a security standpoint.
The other day I was pulling hair from my head trying to configure a Windows Failover Cluster intended for an SQL Server Availability Group setup.
During the cluster validation stage I always got this message:
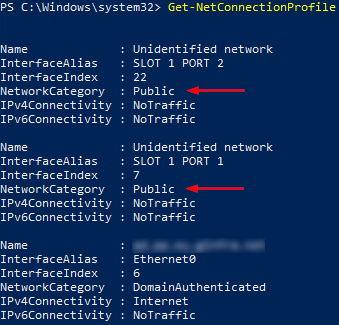
The Windows Firewall on node node01.domain.local is not properly configured for failover clustering.
In particular, the ‘Public’ firewall profile is enabled on adapter ‘node01.domain.local – SLOT 1 PORT 2’.
The ‘Failover Clusters’ rule group is not enabled in firewall profile ‘Public’.
This may prevent some network communication between cluster nodes.
The OS install and networking part was already configured by a someone else and it was a pretty straightforward installation.
The issue turned out to be caused by the 2 NICs we have for iSCSI traffic which did not have a gateway configured.
Windows uses gateways to identify networks. If it doesn’t have a gateway configured, or if it can’t successfully ping it, it will not be able to identify the network it’s connected to and will assume it’s a public one.
Network cards in Windows can be connected to one of these type of networks:
– Public
– Private
– DomainAuthenticated
By default, the public network location type is assigned to any new networks when they are first connected.
A public network is considered to be shared with the world, with no protection between the local computer and any other computer. Therefore, the Windows Firewall rules associated with the public profile are the most restrictive.
As part of the Windows Failover Cluster validation/creation there are checks to verify connectivity (between cluster nodes, active directory, etc.).
These were the settings I had:
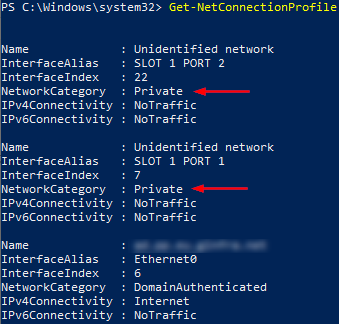
All I needed to do was to move all non-domain network interfaces into the private profile:
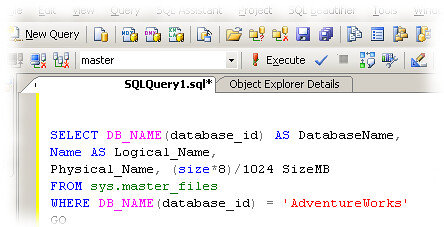
Recently I had the oportunity to test SQL Pretty Printer (Add-In for SSMS). I don’t have to waste time formatting long sql queries. In no time, SQL Pretty Printer does the job
for me. It can also translate the sql code into C#, Java, Php and many other program languages so I can use it in my own programs. SQL Pretty printer is designed to deal with SQL statement used by different Database Such as MSSQL, Oracle, DB2, Informix, Sybase, Postgres, MySQL and so on. The code conforms to most of the entry-level SQL99 Standard.
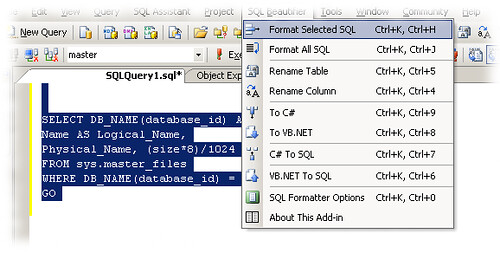
To use this add-in you need to have SQL Server Management Studio (SSMS), with .NET2.0 installed. In sql editor you can use shortcut key (ctrl+k,ctrl+j for all sqls, and ctrl+k, ctrl+h for selected sql). There is also a toolbar with two buttons to format sql or selected sql.
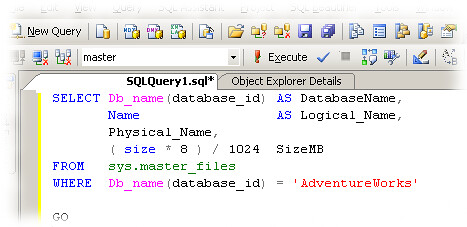
To see it in action, take a look here, where you have some sample code blocks before and after the formatting.